Introducing The Java Batch Processing API And JBeret Implementation
The Jakarta Batch API specification defines the interfaces and workflow to process a job(a usually it’s a data processing job):
- GitHub - eclipse-ee4j/batch-api: The Jakarta Batch project produces the Batch Specification and API.
And here is the homepage of the spec: Jakarta Batch / The Eclipse Foundation
This spec was JSR352 before:
As the introduction written in the spec:
This specification describes the job specification language, Java programming model, and runtime environment for Jakarta Batch. It is designed for use on Jakarta EE platforms, and also in other Java SE environments.
It mainly focuses on describing a workflow and is usually used to implement a data processing workflow. There are several frameworks that implement this spec. Here is a list that shows several implementations:
- JBeret from the WildFly community
- GitHub - quarkiverse/quarkus-jberet: Quarkus Extension for Batch Applications.
- Spring Batch
The JBeret project is from the WildFly community and it is also integrated in the Quarkus project. In this article I’ll briefly introduce the above three implementations, and compare their differences. First let’s see the specification.
Specification
Here is the spec API codebase:
- GitHub - eclipse-ee4j/batch-api: The Jakarta Batch project produces the Batch Specification and API.
The overall class diagram of the spec is shown as below:
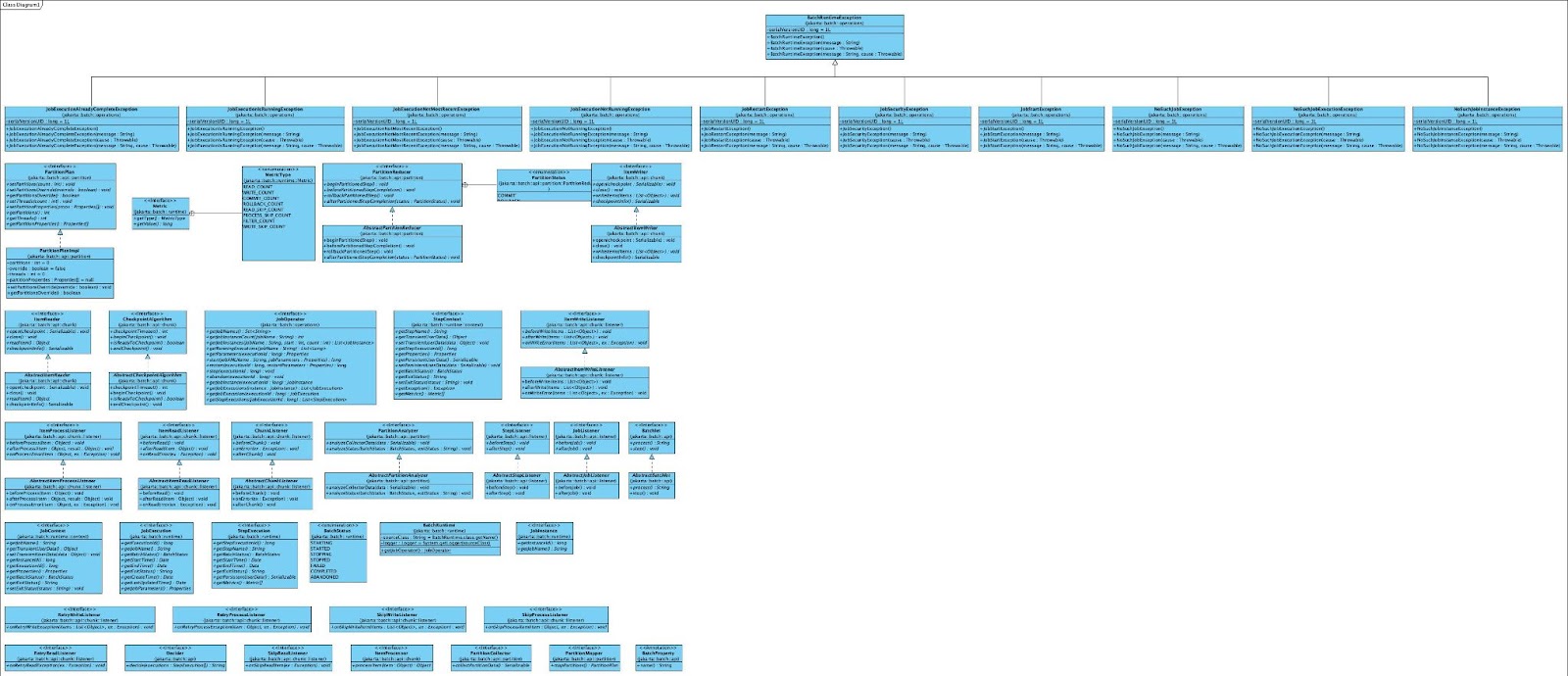
The Job Specification Language is described here:
There are several core concepts in the above spec to define a batch job. For example, here is some code that shows a job definition:
<job id="batchlet-job" xmlns="http://xmlns.jcp.org/xml/ns/javaee" version="1.0">
<step id="batchlet-step">
<batchlet ref="batchlet">
<properties>
<property name="name" value="#{jobParameters['name']}"/>
</properties>
</batchlet>
</step>
</job>
The above job definition is extracted from the quarkus-jberet test code:
- https://github.com/quarkiverse/quarkus-jberet/blob/main/core/deployment/src/test/resources/batchlet.xml
Note: There are currently several versions of the specification:
1.0 is part of Jakarta EE 8. 2.0 is part of Jakarta EE 9. 2.1 is part of Jakarta EE 10.
So if you want to use the latest, the version and the url should be 2.1 and _ / https://jakarta.ee/specifications/batch/2.1
If you want to use batch 2.1, see https://github.com/jberet/jsr352/blob/master/jberet-se/src/test/resources/META-INF/batch-jobs/org.jberet.se.test.injectBatchlet.xml#L13
The reason we are using older version of the specification in the article is because some projects (jberet-support, jberet-rest, etc) currently do not support batch api 2.1 (with
jakarta.*package name) yet. Andjakarta.*api is supported in WildFly Preview only, which is not a Final release yet when this article is written.So to make all the samples here work, the batch api has to be
Jakarta Batch 1.0, which hasjavax.*prefix in API package names. So I will stick with job version 1.0 in this article, which is http://xmlns.jcp.org/xml/ns/javaee
From the above job definition we can see that a job is combined with steps, and in the step there is a batchlet that defines an action to run. A batchlet is an interface that can define an action to run:
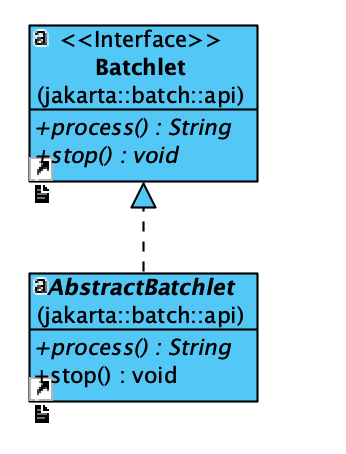
It contains a process() and a stop() interface that allows the user to define the detail actions to take, and the implementation of the Batch API framework will take the responsibility to run the jobs. The batchlet is not the only block that we can use for writing action blocks. Here is another way to define a job:
<job id="chunk-job" xmlns="http://xmlns.jcp.org/xml/ns/javaee" version="1.0">
<step id="chunk-step">
<chunk>
<reader ref="peopleReader"/>
<!-- To make sure we can use the class name too -->
<processor ref="peopleProcessor"/>
<writer ref="peopleWriter"/>
</chunk>
</step>
</job>
(The above job definition is extracted from: https://github.com/quarkiverse/quarkus-jberet/blob/main/core/deployment/src/test/resources/chunk.xml)
From the above we can see that the step contains an element called chunk. Inside the chunk, it contains a reader, a processor, and a writer. These definitions are also defined inside the API spec:
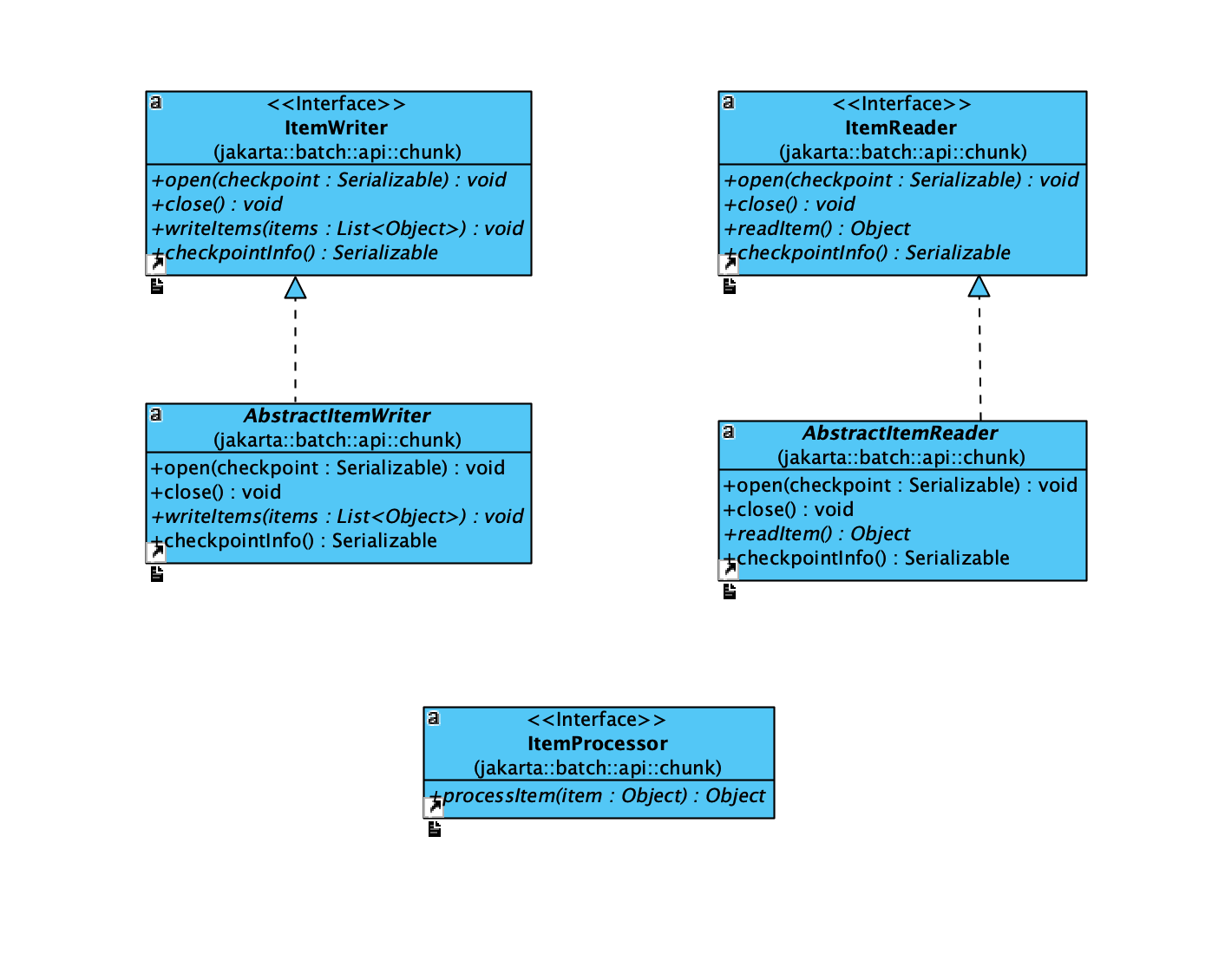
As we can see above, different from the batchlet, which only has a process() method and a stop() method, a chunk divides actions into three parts: reader, processor and writer. This is more suitable for more complex workflows.
There are many more parts in the Batch API spec(listener for example), and you can always learn them by using a framework and see their tests or examples.
The Batch API just defines the interfaces, and it is the framework’s duty to implement the interfaces. In addition, the API spec doesn’t define the interfaces exactly the same as the Job Specification Language. For example, here is the Chunk implementation in JBeret:
Here is the class diagram of the jberet-core (Only part of the classes are included):
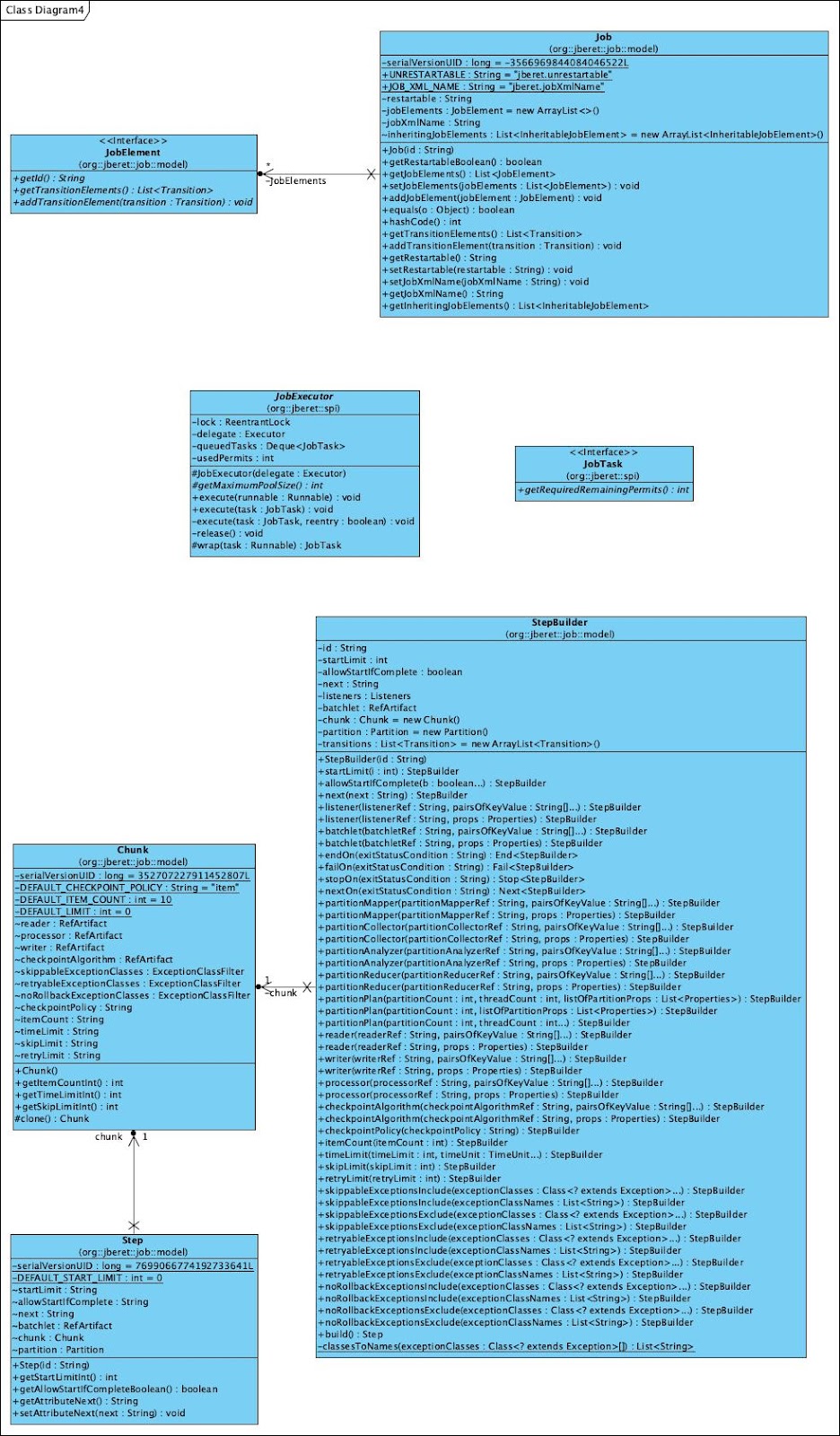
Until now we have learned about the Batch API, and checked several job definition examples, and had a brief look at JBeret implementation of the API. Next let’s check several different frameworks and their usages.
Introducing JBeret
There are several projects that implements the specification, and in this article I will focus on introducing the JBeret project provided by the WildFly community:
This project is used in both WildFly and Quarkus. We will have a look at the project firstly, and then see how it is used in WildFly and Quarkus. JBeret also implements the Batch API, and here is the diagram of the core part of JBeret codebase:
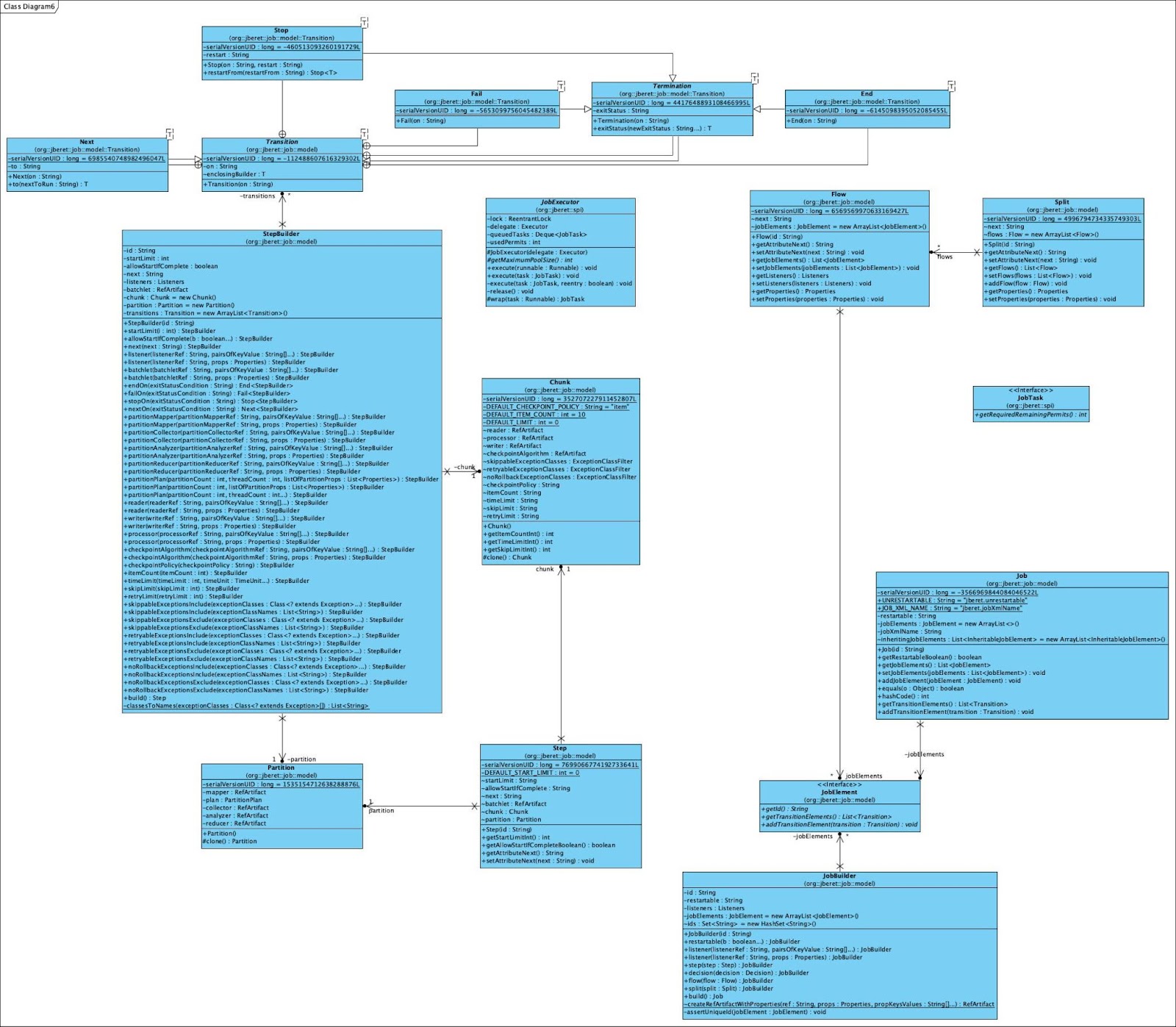
We can see JBeret has created its own implementation to support the Batch API. To check how to use the framework, JBeret has provided a sample project here:
We can clone the above repository and use one of the above examples for demonstration:
$ git clone https://github.com/jberet/jberet-wildfly-samples.git
Please note currently the codebase can be built with JDK 11:
➤ java -version
openjdk version "11.0.2" 2019-01-15
OpenJDK Runtime Environment 18.9 (build 11.0.2+9)
OpenJDK 64-Bit Server VM 18.9 (build 11.0.2+9, mixed mode)
To build the project, we can run the following command:
➤ mvn clean install
If everything goes fine, the project will be built:
[INFO] ------------------------------------------------------------------------
[INFO] Reactor Summary for wildfly-jberet-samples 1.4.0.Alpha-SNAPSHOT:
[INFO]
[INFO] wildfly-jberet-samples ............................. SUCCESS [ 3.602 s]
[INFO] jberet-samples-common .............................. SUCCESS [ 2.800 s]
[INFO] batchproperty ...................................... SUCCESS [ 1.787 s]
[INFO] throttle ........................................... SUCCESS [ 0.659 s]
[INFO] csv2json ........................................... SUCCESS [ 2.666 s]
[INFO] xml2json ........................................... SUCCESS [ 0.731 s]
[INFO] xml2jsonLookup ..................................... SUCCESS [ 0.231 s]
[INFO] csv2mongoLookup .................................... SUCCESS [ 0.224 s]
[INFO] excelstream2csv .................................... SUCCESS [ 1.406 s]
[INFO] deserialization .................................... SUCCESS [ 0.812 s]
[INFO] restAPI Maven Webapp ............................... SUCCESS [ 1.217 s]
[INFO] restReader ......................................... SUCCESS [ 0.717 s]
[INFO] restWriter ......................................... SUCCESS [ 0.929 s]
[INFO] scheduleExecutor ................................... SUCCESS [ 0.608 s]
[INFO] scheduleTimer ...................................... SUCCESS [ 0.443 s]
[INFO] purgeJdbcRepository Maven Webapp ................... SUCCESS [ 0.439 s]
[INFO] camelReaderWriter .................................. SUCCESS [ 1.217 s]
[INFO] clusterChunkServlet ................................ SUCCESS [ 2.220 s]
[INFO] clusterChunkEJB .................................... SUCCESS [ 1.511 s]
[INFO] clusterInfinispan .................................. SUCCESS [ 1.195 s]
[INFO] batchlet-singleton ................................. SUCCESS [ 0.249 s]
[INFO] ------------------------------------------------------------------------
[INFO] BUILD SUCCESS
[INFO] ------------------------------------------------------------------------
[INFO] Total time: 26.129 s
[INFO] Finished at: 2022-11-11T23:46:55+08:00
[INFO] ------------------------------------------------------------------------
Next we can pick one of the examples from the project, and try to deploy it into WildFly to see how it’s running. In this article I pick the csv2json example for demonstration:
➤ pwd
/Users/weli/works/jberet-wildfly-samples
➤ ls csv2json
pom.xml src target
This example shows how to read a CSV file by using a reader and convert it to JSON file by using a writer. As the screenshot shown above, this sample project contains three XML files:
csv2json.xmlbatch.xmlweb.xml
In batch.xml, it defines a reader and a writer for use:
<?xml version="1.0" encoding="UTF-8"?>
<batch-artifacts xmlns="http://xmlns.jcp.org/xml/ns/javaee"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://xmlns.jcp.org/xml/ns/javaee http://xmlns.jcp.org/xml/ns/javaee/batchXML_1_0.xsd">
<ref id="csvItemReader" class="org.jberet.support.io.CsvItemReader" />
<ref id="jsonItemWriter" class="org.jberet.support.io.JsonItemWriter" />
</batch-artifacts>
The above two classes are from another project of JBeret:
- https://github.com/jberet/jberet-support
Here is the the project introduction:
This module provides reusable batch components for common batch tasks.
In the sample project it uses CsvItemReader(jberet-support/CsvItemReader.java at master · jberet/jberet-support · GitHub) and JsonItemWriter(https://github.com/jberet/jberet-support/blob/master/src/main/java/org/jberet/support/io/JsonItemWriter.java) from the above project.
Here is the class diagram of the reader and writer:

As we can see, the CsvItemReader can read the CSV file, and the JsonItemWriter can convert a list of objects into JSON format and output into a configured destination(File for example).
Now let’s go back to the sample project, and check the csv2json.xml:
<?xml version="1.0" encoding="UTF-8"?>
<job id="csv2json" xmlns="http://xmlns.jcp.org/xml/ns/javaee"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://xmlns.jcp.org/xml/ns/javaee http://xmlns.jcp.org/xml/ns/javaee/jobXML_1_0.xsd"
version="1.0">
<step id="csv2json.step1" parent="csvItemReaderStep" jsl-name="csvItemReader">
<chunk>
<writer ref="jsonItemWriter">
<properties>
<property name="resource" value="#{systemProperties['java.io.tmpdir']}/movies.csv.json"/>
<property name="writeMode" value="overwrite"/>
</properties>
</writer>
</chunk>
</step>
</job>
In the above XML file, it defines the job. It uses csvItemReader defined in batch.xml(which is the jberet-support/CsvItemReader.java at master · jberet/jberet-support · GitHub in jberet-support). It reads a CSV file and convert it to a Java object:
@Override
public Object readItem() throws Exception {
if (delegateReader.getRowNumber() > this.end) {
return null;
}
final Object result;
if (delegateReader instanceof org.supercsv.io.ICsvBeanReader) {
if (cellProcessorInstances.length == 0) {
result = ((ICsvBeanReader) delegateReader).read(beanType, getNameMapping());
} else {
result = ((ICsvBeanReader) delegateReader).read(beanType, getNameMapping(), cellProcessorInstances);
}
if (!skipBeanValidation) {
ItemReaderWriterBase.validate(result);
}
} else if (delegateReader instanceof ICsvListReader) {
if (cellProcessorInstances.length == 0) {
result = ((ICsvListReader) delegateReader).read();
} else {
result = ((ICsvListReader) delegateReader).read(cellProcessorInstances);
}
} else {
if (cellProcessorInstances.length == 0) {
result = ((ICsvMapReader) delegateReader).read(getNameMapping());
} else {
result = ((ICsvMapReader) delegateReader).read(getNameMapping(), cellProcessorInstances);
}
}
return result;
}
The reader will Object to jsonItemWriter(which is the JsonItemWriter defined in batch.xml), and it outputs the result to the JSON file:
#{systemProperties['java.io.tmpdir']}/movies.csv.json
The file to read is:
The file to read is defined in the parent of the above reader step in csv2json.xml:
<?xml version="1.0" encoding="UTF-8"?>
<job id="csv2json" xmlns="http://xmlns.jcp.org/xml/ns/javaee"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://xmlns.jcp.org/xml/ns/javaee http://xmlns.jcp.org/xml/ns/javaee/jobXML_1_0.xsd"
version="1.0">
<step id="csv2json.step1" parent="csvItemReaderStep" jsl-name="csvItemReader">
<chunk>
<writer ref="jsonItemWriter">
<properties>
<property name="resource" value="#{systemProperties['java.io.tmpdir']}/movies.csv.json"/>
<property name="writeMode" value="overwrite"/>
</properties>
</writer>
</chunk>
</step>
</job>
The parent step is called csvItemReaderStep. This parent step is defined from the jberet-wildfly-samples/jberet-samples-common at master · jberet/jberet-wildfly-samples · GitHub project, which is a dependency inside the pom.xml file:
<dependency>
<groupId>org.jberet.samples</groupId>
<artifactId>jberet-samples-common</artifactId>
<version>${project.version}</version>
</dependency>
And the XML file to define the job is here:
<?xml version="1.0" encoding="UTF-8"?>
<job id="csvItemReader" xmlns="http://xmlns.jcp.org/xml/ns/javaee"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://xmlns.jcp.org/xml/ns/javaee http://xmlns.jcp.org/xml/ns/javaee/jobXML_1_0.xsd"
version="1.0">
<step id="csvItemReaderStep" abstract="true">
<chunk>
<reader ref="csvItemReader">
<properties>
<property name="resource" value="https://raw.githubusercontent.com/jberet/jberet-support/master/src/test/resources/movies-2012.csv"/>
<property name="beanType" value="org.jberet.samples.wildfly.common.Movie"/>
<property name="nameMapping" value="rank,tit,grs,opn"/>
<property name="cellProcessors" value= "ParseInt; NotNull, StrMinMax(1, 100); DMinMax(1000000, 1000000000); ParseDate('yyyy-MM-dd')"/>
</properties>
</reader>
</chunk>
</step>
</job>
Please note that this parent inheritance feature is a non-standard feature in JBeret (not in batch spec). We will see how this file is read after the sample project is deployed and run on the WildFly server later. The last XML file to check is the web.xml file:
<web-app version="3.1"
xmlns="http://xmlns.jcp.org/xml/ns/javaee"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://xmlns.jcp.org/xml/ns/javaee http://xmlns.jcp.org/xml/ns/javaee/web-app_3_1.xsd">
<servlet-mapping>
<servlet-name>javax.ws.rs.core.Application</servlet-name>
<url-pattern>/api/*</url-pattern>
</servlet-mapping>
</web-app>
It exposes the JBeret as REST services, which is enabled by the jberet-rest project:
With the above web.xml, we can start the job and monitor the job execution status. Now we have analyzed the project structure, we can run the sample project with the following command:
$ mvn wildfly:run
Because the sample project has embedded WildFly plugin in pom.xml:
<plugin>
<groupId>org.wildfly.plugins</groupId>
<artifactId>wildfly-maven-plugin</artifactId>
...
</plugin>
So the above command will download a WildFly Distribution, start the server, and then deploy the sample project onto the server. If the command run successfully, we can see the server is started and the project is deployed:
00:26:15,875 INFO [org.wildfly.extension.undertow] (ServerService Thread Pool -- 4) WFLYUT0021: Registered web context: '/csv2json' for server 'default-server'
00:26:16,031 INFO [org.jboss.as.server] (management-handler-thread - 1) WFLYSRV0010: Deployed "csv2json.war" (runtime-name : "csv2json.war")
Now we can run the test in the sample project to query the service. Here is the command to start the test:
➤ mvn test -Pwildfly -Dtest=Csv2JsonIT
If the above command is running correctly, you should see the test is run and passed:
[INFO] -------------------------------------------------------
[INFO] T E S T S
[INFO] -------------------------------------------------------
[INFO] Running org.jberet.samples.wildfly.csv2json.Csv2JsonIT
Starting test: testCsv2Json
[INFO] Tests run: 1, Failures: 0, Errors: 0, Skipped: 0, Time elapsed: 5.533 s - in org.jberet.samples.wildfly.csv2json.Csv2JsonIT
[INFO]
[INFO] Results:
[INFO]
[INFO] Tests run: 1, Failures: 0, Errors: 0, Skipped: 0
[INFO]
[INFO] ------------------------------------------------------------------------
[INFO] BUILD SUCCESS
[INFO] ------------------------------------------------------------------------
[INFO] Total time: 7.897 s
[INFO] Finished at: 2022-11-14T01:14:20+08:00
[INFO] ------------------------------------------------------------------------
From the server side, we can see from the log output that how the job read the input file and convert it to output file:
01:15:07,240 INFO [org.jberet.support] (Batch Thread - 4) JBERET060501: Opening resource https://raw.githubusercontent.com/jberet/jberet-support/master/src/test/resources/movies-2012.csv in class org.jberet.support.io.CsvItemReader
01:15:07,240 INFO [org.jberet.support] (Batch Thread - 4) JBERET060501: Opening resource /var/folders/0m/csp222ks3g17w_2qqrcw8ktm0000gn/T//movies.csv.json in class org.jberet.support.io.JsonItemWriter
01:15:07,256 INFO [org.jberet.support] (Batch Thread - 4) JBERET060502: Closing resource /var/folders/0m/csp222ks3g17w_2qqrcw8ktm0000gn/T//movies.csv.json in class org.jberet.support.io.JsonItemWriter
01:15:07,257 INFO [org.jberet.support] (Batch Thread - 4) JBERET060502: Closing resource https://raw.githubusercontent.com/jberet/jberet-support/master/src/test/resources/movies-2012.csv in class org.jberet.support.io.CsvItemReader
The test calls the service provided by JBeret REST and check the job execution result:
@Test
public void testCsv2Json() throws Exception {
startJobCheckStatus(jobName, null, 5000, BatchStatus.COMPLETED);
}
It encapsulates the request detail, but we can use Wireshark to analyze the HTTP call to see what the request/response is. Here is the first request the test made to the server side:
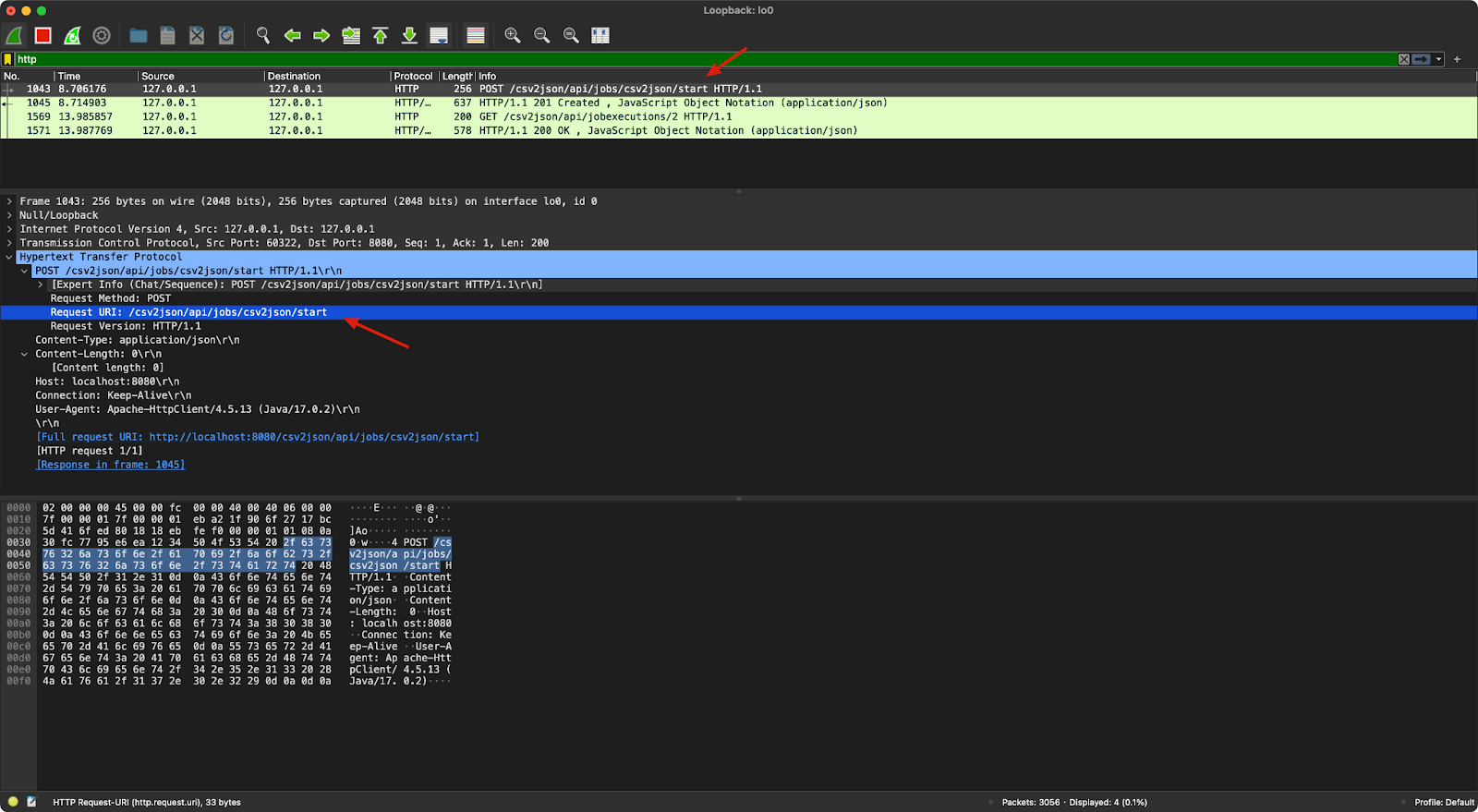
We can see the test called /jobs/csv2json/start to start the job. Then we can see the server returned that the job is created:
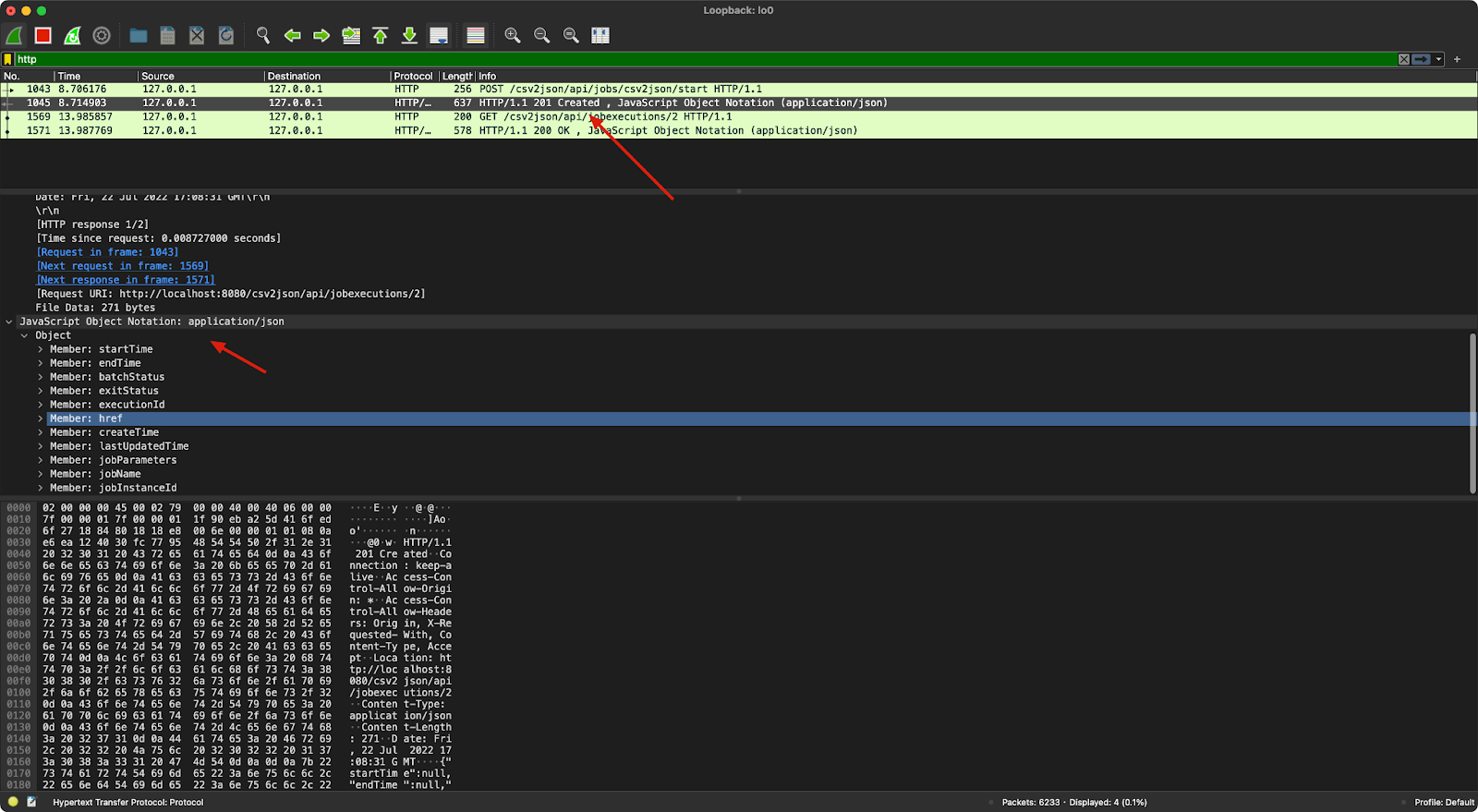
We can see JBeret REST returns multiple fields about the job, such as startTime, endTime, and jobStatus. Then the test query the job status:
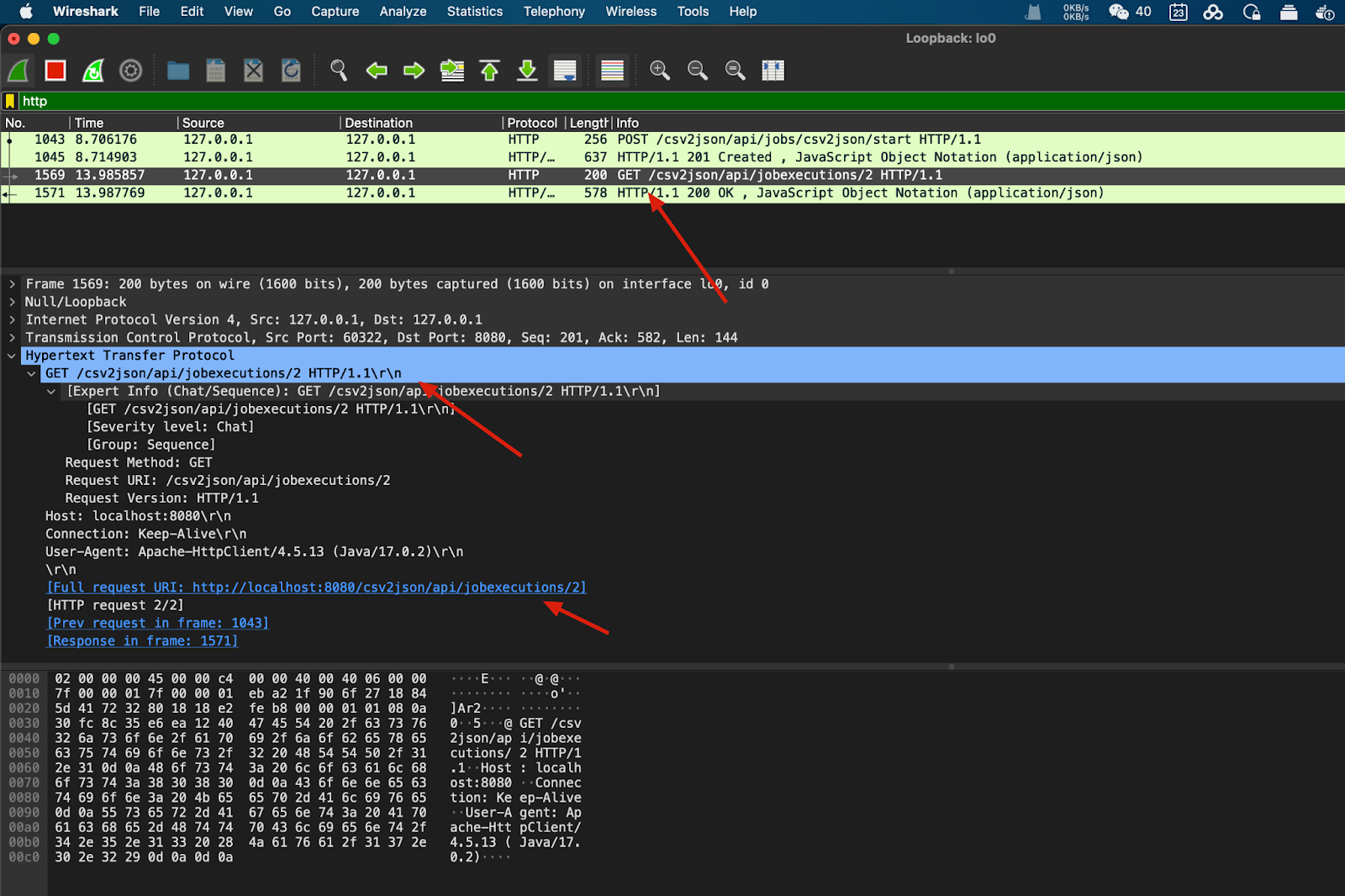
The request URI is /api/jobexecutions/2, which returns the job status:
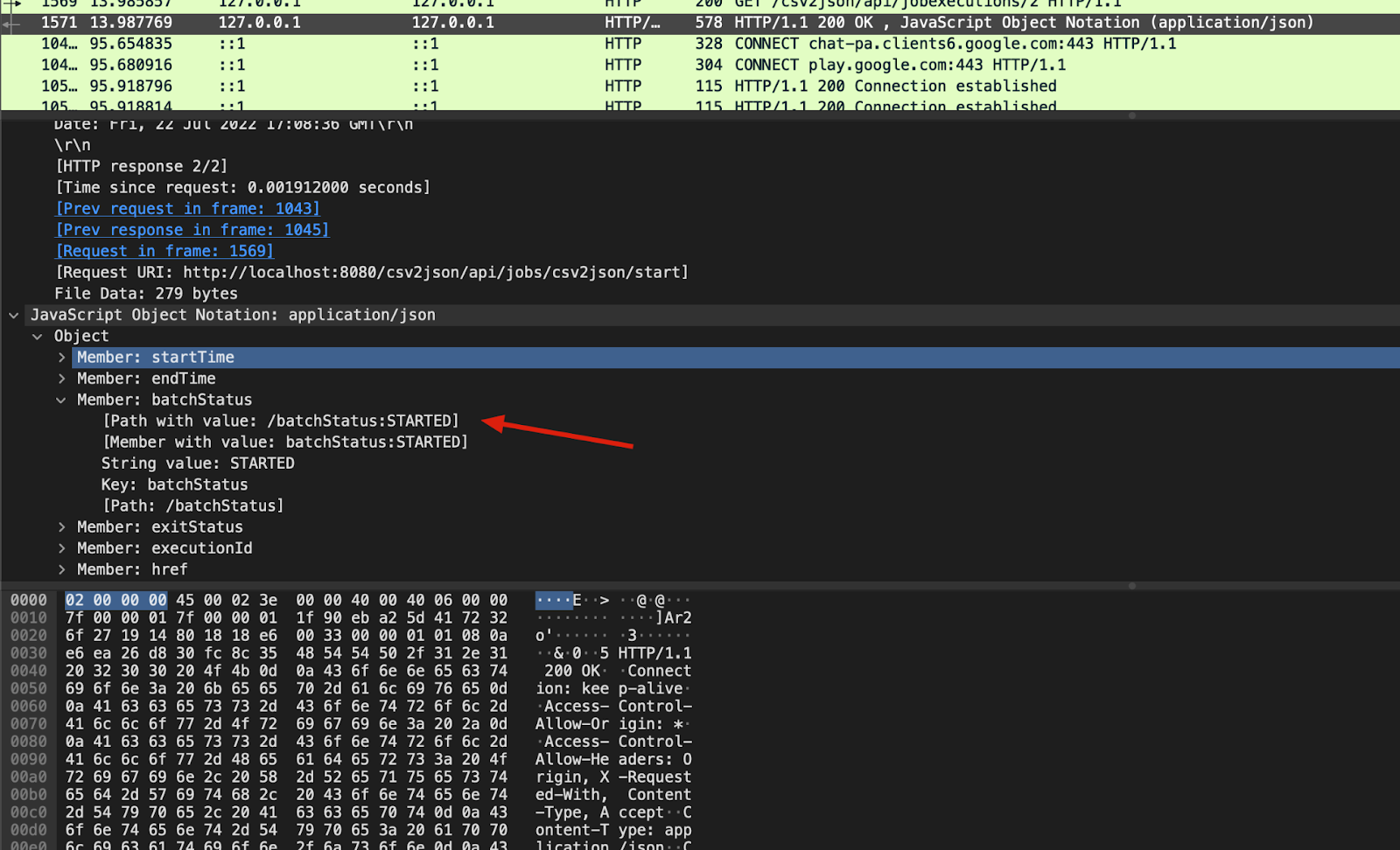
After the job is done, we can check the generated JSON file and its content:
➤ cat /var/folders/0m/csp222ks3g17w_2qqrcw8ktm0000gn/T//movies.csv.json | head
[ {
"rank" : 1,
"tit" : "Marvel's The Avengers",
"grs" : 6.2335791E8,
"opn" : 1336060800000,
"rating" : null
}, {
"rank" : 2,
"tit" : "The Dark Knight Rises",
"grs" : 4.48139099E8,
As you can see the generated JSON file is converted from the CSV file.
Summary
In this article, we have learned about the Jakarta Batch API (previously JavaEE spec), and we have looked at the JBeret project and its usages with WildFly. In addition, each implementation has its own features that are defined outside the spec. For example, the JBeret has parent job support and the REST API that can be used out of the box.